Asagiは、最大で14Bのパラメータを持つ、日本語に特化したオープンなVision&Languageモデル(VLM)です。
日本語VLMを開発するにあたっての最大の課題は、モデルを学習するための大規模な日本語の画像・テキストペアデータセットが不足しているということでした。
そこで、本研究では、Webからクロールした画像データなどを活用し、英語のVLMや日本語大規模言語モデル(LLM)を用いて、日本語のデータセットを新規に合成してモデルの学習に利用しました。
本研究のデータ合成戦略の特色は、出力物の利用に制限のあるLLM(GPT-4oなど)を合成プロセスにおいて使用していないという点です。
結果として、今回構築したAsagiモデルは、高い性能を達成しつつ、従来の日本語VLMよりもオープンな形で提供することが可能となりました。
なお、本研究については、3月に開催される言語処理学会第31回年次大会(NLP2025)にて発表を予定しています(3月11日(火) 13:00-14:30 Q3セッション)。
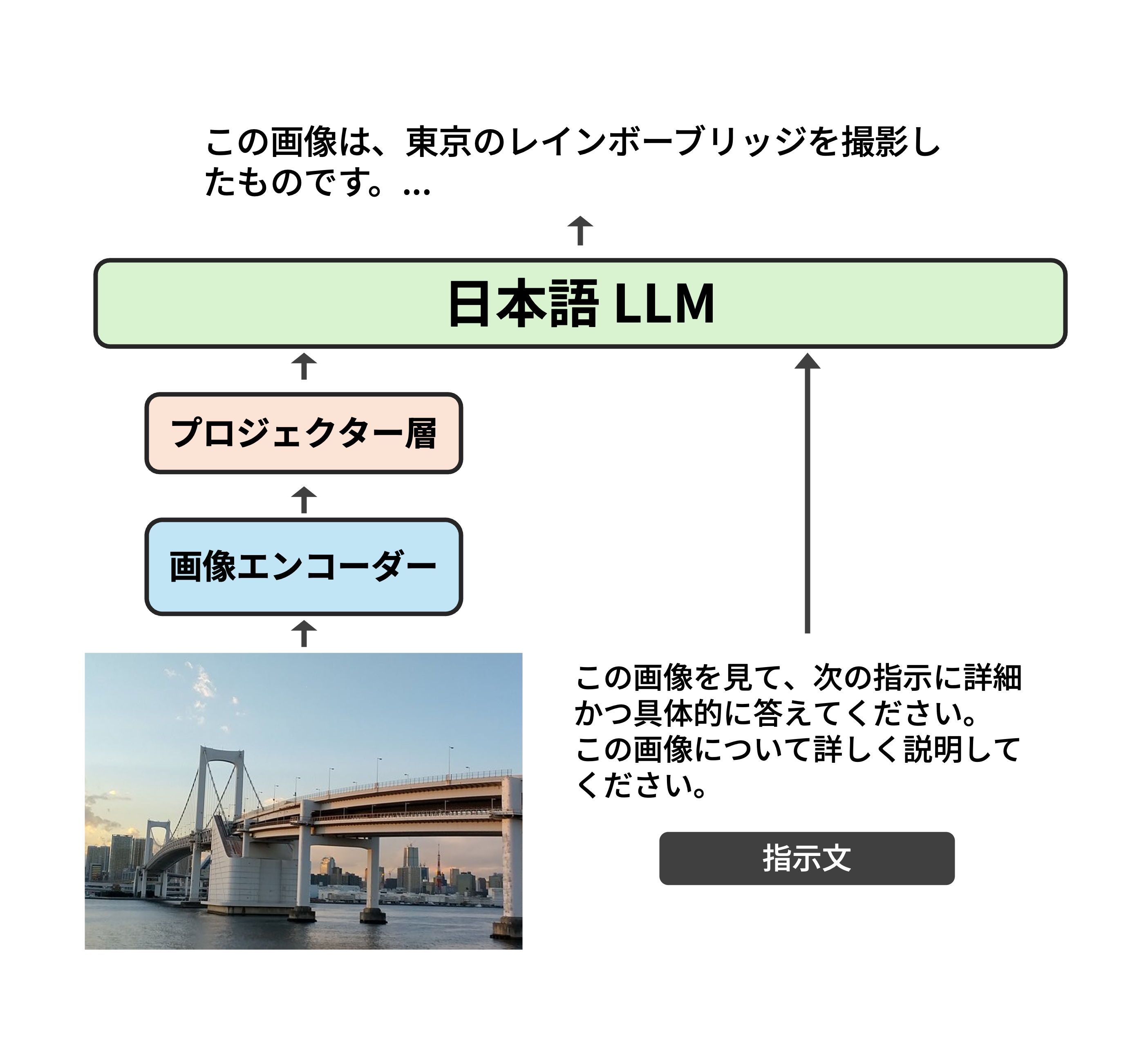
今回リリースするモデルは、LLaVA[1]をベースとしたモデル構成となっています。
LLaVAは、画像エンコーダーとLLM、両者を接続する2層の線形層から構成されるモデルです。
画像エンコーダーには、SigLIPモデル[2]を用いています。
LLMは、LLM-jpによってリリースされた日本語LLM[3]を使用しています。
LLMのパラメータサイズによって、Asagiモデルにはいくつかのバリエーションがあります。
| モデル名 | 総パラメータ数 | 画像エンコーダー | LLM |
|---|---|---|---|
| Asagi-2B | 2.3B | siglip-so400m-patch14-384 | llm-jp-3-1.8b-instruct |
| Asagi-4B | 4.2B | siglip-so400m-patch14-384 | llm-jp-3-3.7b-instruct |
| Asagi-8B | 7.8B | siglip-so400m-patch14-384 | llm-jp-3-7.2b-instruct |
| Asagi-14B | 14.2B | siglip-so400m-patch14-384 | llm-jp-3-13b-instruct |
Asagiモデルの学習には、Webから完全新規でクロールした日本語Webサイトの画像データを活用しました。
データセットを構築する際には、画像の内容に基づく高品質なテキストデータを得るため、英語VLM(Phi-3.5-vision-instruct)や日本語LLM(CALM3-22B-Chat)を用いたデータ合成を行っています。
新規に合成したデータと、既存の日本語データセット、日本語に翻訳した英語データセットを合わせて、約2000万件のデータで学習を行いました。
データセットの詳細については、論文をご参照ください。
モデルの訓練には、H100 GPUが8枚搭載された計算ノードを最大24ノード用いました。
Megatron-LMを大規模VLMの学習に向けて拡張し、大規模モデルの効率的な学習を実現しています。
実装は、GitHubで公開しています。






Asagiモデルの性能を他の日本語VLMと比較した結果を示します。評価スコアの計算には、llm-jp-eval-mmライブラリを使用しました。
なお、†印のモデルは、GPT-4によって生成されたデータを学習に用いていないモデルです。
太字は、そのベンチマークで最高のスコアであることを示しており、下線は、GPTによって生成されたデータを学習に用いていないモデルの中で最高のスコアであることを示しています。
| Heron-Bench | JA-VLM-Bench-In-the-Wild | JA-VG-VQA-500 | ||||
|---|---|---|---|---|---|---|
| Model | LM Size | LLM (%) | ROUGE-L | LLM (/5.0) | ROUGE-L | LLM (/5.0) |
| Japanese InstructBLIP Alpha† | 7B | 14.0 | 20.8 | 2.42 | - | - |
| Japanese Stable VLM† | 7B | 24.2 | 23.3 | 2.47 | - | - |
| LLaVA-CALM2-SigLIP† | 7B | 43.3 | 47.2 | 3.15 | 17.4 | 3.21 |
| Llama-3-EvoVLM-JP-v2 | 8B | 39.3 | 41.4 | 2.92 | 23.5 | 2.96 |
| VILA-jp | 13B | 57.2 | 52.3 | 3.69 | 16.2 | 3.62 |
| Asagi-2B† | 1.8B | 44.7 | 48.8 | 3.26 | 53.7 | 3.69 |
| Asagi-4B† | 3.7B | 49.3 | 49.6 | 3.38 | 55.6 | 3.78 |
| Asagi-8B† | 7.2B | 54.7 | 49.4 | 3.45 | 56.43 | 3.84 |
| Asagi-14B† | 13B | 55.8 | 50.8 | 3.44 | 56.8 | 3.84 |
| GPT-4o | - | 87.6 | 37.6 | 3.85 | 12.1 | 3.58 |
本研究では、合成データセットを活用して、日本語VLMの構築を行いました。
日本語VLMとしては、過去最大級のデータセットを用いて学習を行っているため、多様な指示や質問に対応可能なモデルに仕上がっています。
また、ユーザーの使いやすさを考慮し、2Bモデルなどの軽量なモデルも提供しています。
ぜひ、モデルをダウンロードして、Asagiモデルの性能を体験してみてください!
@inproceedings{asagi2024,
author = {上原康平 and 黒瀬優介 and 安道健一郎 and Chen Jiali and Gao Fan and 金澤爽太郎 and 坂本拓彌 and 竹田悠哉 and Yang Boming and Zhao Xinjie and 村尾晃平 and 吉田浩 and 田村孝之 and 合田憲人 and 喜連川優 and 原田達也},
title = {Asagi: 合成データセットを活用した大規模日本語VLM},
booktitle = {言語処理学会第31回年次大会},
year = {2025}
}